I saw that the TNG Jupyter released a dataset named 'TNG50 Milky Way+Andromeda(MW/M31) Sample', and its cutouts data include six fields(fig.1). I noticed that the 'Data Specifications' page mentioned 'the cutout headers contain a subset of information from the header of the main snapshot file.In addition there are two added entries (fig.2) '.but when I called it, I found that the 'header' dataset is empty and does not contain the 'SubfindID_This_Snapshot' field(fig.1). Why is this the case?
Additionally, if I want to track the data by myself using the loadTree method instead of using the cutouts data, can I assume that the SubfindID obtained from onlyMPB is its ID in the previous snapshot? For example, one of the subhalos filtered out in MWM31s has an ID of 372754. In *sims.TNG/TNG50-1/postprocessing/MWM31s/cutouts*, it is always named 372754, but its SubfindID is actually 372754 only in snapshot 99, not in snapshot 98. Can I find the actual SubfindID of this subhalo in snapshot 98 using the method above? (For instance, if the data loaded by loadTree(onlyMPB) is array([372754, 372305, ...]), then the actual SubfindID of this subhalo in snapshot 98 would be 372305.fig.3)
Another question is, can this method ensure that the subhalo remains the first subhalo of the halo?And for satellite galaxies of MWM31s, can I also assume that the SubfindID obtained from onlyMPB is the ID of the satellite during its evolutionary process?
I would be very grateful if you could answer my question.
Zhang
!
怡远 张
14 Nov '24
Another question is why some subhalos have lhalotree data but no sublink tree,such as the subhalo536161 in snapshot99 of TNG50-1
Dylan Nelson
14 Nov '24
(1) The contents of Header are attributes, not datasets. You can read about the difference and how to see attributes in e.g. the h5py documentation.
(2) The MWM31 cutouts are given in terms of their z=0 subhalo IDs. Following these galaxies across time, their subhalo IDs at different snapshots are different. You can indeed obtain these IDs using the MPB of the merger tree (or with the "SubfindID_ThisSnapshot" attribute).
(3) You can also track satellites using the merger trees.
(4) Not all subhalos are in the trees, although this should be very rare for massive galaxies. You can find more information in the tree documentation and related papers.
Hi Dylan! I have some simple questions to bother you !
How could I distinguish the cold gas and hot gas in galaxy?(I found no temperature data in either groupcat.subhalo or snapshot.parttype1)And what criteria do you suggest to set to distinguish between hot and cold gases ?
When I use the SubhaloMassType[0] to calculate the density of the subhalo bounded gas , which radius should I choose? (maybe the R_crit200 for central subhalo?)
Thank you very much!
Dylan Nelson
23 Jan '25
You can calculate the temperature of PartType0 (gas) following this FAQ answer.
Then you can separate between hot and cold based on a constant number, or based on a fraction of the virial temperature of the halo. A common choice is 10^4.5 or 10^5.0 as the dividing line between hot and cold for MW mass halos, since this separates the two fairly well.
For density I would take the mean of PartType0/Density, of whatever gas cells (in whatever radius) you want.
Hello,
I saw that the TNG Jupyter released a dataset named 'TNG50 Milky Way+Andromeda(MW/M31) Sample', and its cutouts data include six fields(fig.1). I noticed that the 'Data Specifications' page mentioned 'the cutout headers contain a subset of information from the header of the main snapshot file.In addition there are two added entries (fig.2) '.but when I called it, I found that the 'header' dataset is empty and does not contain the 'SubfindID_This_Snapshot' field(fig.1). Why is this the case?
Additionally, if I want to track the data by myself using the
loadTreemethod instead of using the cutouts data, can I assume that theSubfindIDobtained fromonlyMPBis its ID in the previous snapshot? For example, one of the subhalos filtered out in MWM31s has an ID of 372754. In*sims.TNG/TNG50-1/postprocessing/MWM31s/cutouts*, it is always named 372754, but itsSubfindIDis actually 372754 only in snapshot 99, not in snapshot 98. Can I find the actualSubfindIDof this subhalo in snapshot 98 using the method above? (For instance, if the data loaded byloadTree(onlyMPB)isarray([372754, 372305, ...]), then the actualSubfindIDof this subhalo in snapshot 98 would be 372305.fig.3)Another question is, can this method ensure that the subhalo remains the first subhalo of the halo?And for satellite galaxies of MWM31s, can I also assume that the
SubfindIDobtained fromonlyMPBis the ID of the satellite during its evolutionary process?I would be very grateful if you could answer my question.
Zhang


!
Another question is why some subhalos have lhalotree data but no sublink tree,such as the subhalo536161 in snapshot99 of TNG50-1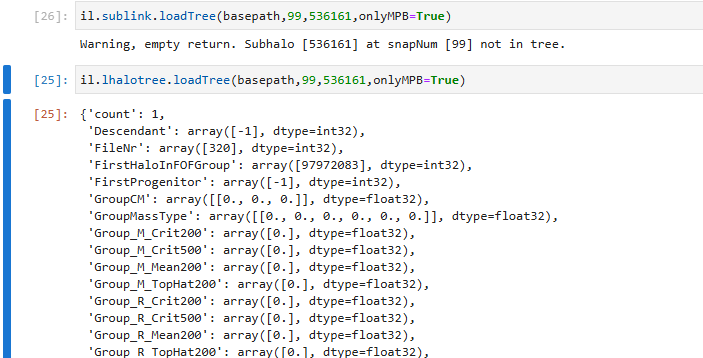
(1) The contents of
Headerare attributes, not datasets. You can read about the difference and how to see attributes in e.g. the h5py documentation.(2) The MWM31 cutouts are given in terms of their z=0 subhalo IDs. Following these galaxies across time, their subhalo IDs at different snapshots are different. You can indeed obtain these IDs using the MPB of the merger tree (or with the "SubfindID_ThisSnapshot" attribute).
(3) You can also track satellites using the merger trees.
(4) Not all subhalos are in the trees, although this should be very rare for massive galaxies. You can find more information in the tree documentation and related papers.
Thank you for your clear and organized response!
Hi Dylan! I have some simple questions to bother you !
How could I distinguish the cold gas and hot gas in galaxy?(I found no temperature data in either groupcat.subhalo or snapshot.parttype1)And what criteria do you suggest to set to distinguish between hot and cold gases ?
When I use the SubhaloMassType[0] to calculate the density of the subhalo bounded gas , which radius should I choose? (maybe the R_crit200 for central subhalo?)
Thank you very much!
You can calculate the temperature of PartType0 (gas) following this FAQ answer.
Then you can separate between hot and cold based on a constant number, or based on a fraction of the virial temperature of the halo. A common choice is 10^4.5 or 10^5.0 as the dividing line between hot and cold for MW mass halos, since this separates the two fairly well.
For density I would take the mean of
PartType0/Density, of whatever gas cells (in whatever radius) you want.